Il existe plusieurs manières de créer un nuage de mots en Python. Tout dépend de se que l’on veut. Nous allons en discuter ici.
Nuage de mots en Python: le module wordcloud
Si vous aimez les solutions clé en main, le module wordcloud est fait pour vous.
En effet, il vous offrira la possibilité de créer un nuage de mots très rapidement.
Dans cet article, je vais utiliser un fichier texte nommé tout simplement « texte.txt ».
Exemple 1 d’utilisation de WordCloud: nuage de mots en Python
from wordcloud import WordCloud
import matplotlib.pyplot as plt
Fichier = open('texte.txt', 'r' , encoding='utf-8')
texte = Fichier.read()
Fichier.close()
wordcloud = WordCloud(background_color = 'white', max_words = 50).generate(texte)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()C’est l’utilisation la plus basique:
- On lit le fichier, contenant un texte quelconque;
- on construit un nuage de mots à l’aide de la fonction WordCloud
- On affiche le nuage de mots à l’aide de matplotlib
Et cela donne:

Force est de constater que le résultat est brut: dans la langue française, beaucoup de mots sont répétés (articles, préposition, etc.). Il faut donc, pour que le nuage de mots soit optimal, ignorer ces mots: on utilise l’option « stopwords » de la fonction WordCloud:
Exemple 2 d’utilisation de WordCloud: exclusion de mots
from wordcloud import WordCloud
import matplotlib.pyplot as plt
Fichier = open('texte.txt', 'r' , encoding='utf-8')
texte = Fichier.read()
Fichier.close()
mots_exclus = ['d', 'du', 'de', 'la', 'des', 'le', 'et', 'est', 'elle', 'une', 'en', 'que', 'aux', 'qui', 'ces', 'les', 'dans', 'sur', 'l', 'un', 'pour', 'par', 'il', 'ou', 'à', 'ce', 'a', 'sont', 'cas', 'plus', 'leur', 'se', 's', 'vous', 'au', 'c', 'aussi', 'toutes', 'autre', 'comme']
wordcloud = WordCloud(background_color = 'white', stopwords = mots_exclus, max_words = 50).generate(texte)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
C’est déjà nettement mieux: seuls les mots importants du texte sont retenus.
Exemple 3 d’utilisation de WordCloud: donner une forme au nuage
Maintenant, si l’on veut mettre un peu de fun dans ce nuage, on peut lui donner une forme prédéterminée. Par exemple, à l’aide de l’image suivante:

on peut donner une forme de cœur à notre nuage:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
Fichier = open('texte.txt', 'r' , encoding='utf-8')
texte = Fichier.read()
Fichier.close()
mask = np.array(Image.open("coeur.png"))
mask[mask == 1] = 255
mots_exclus = ['d', 'du', 'de', 'la', 'des', 'le', 'et', 'est', 'elle', 'une', 'en', 'que', 'aux', 'qui', 'ces', 'les', 'dans', 'sur', 'l', 'un', 'pour', 'par', 'il', 'ou', 'à', 'ce', 'a', 'sont', 'cas', 'plus', 'leur', 'se', 's', 'vous', 'au', 'c', 'aussi', 'toutes', 'autre', 'comme']
wordcloud = WordCloud(background_color = 'white', stopwords = mots_exclus, max_words = 50, mask = mask).generate(texte)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()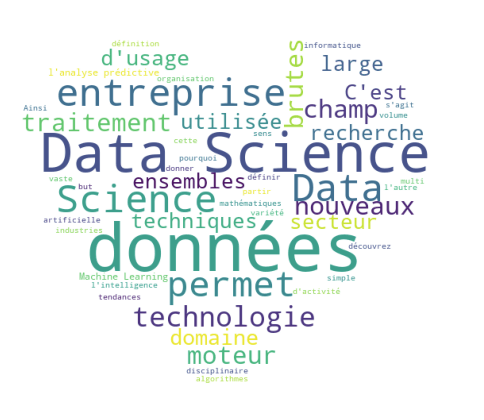
Ce qui se passe ici, c’est que Numpy convertit notre image en tableau numérique, en matrice. Le nuage de mots est alors imaginé à partir de cette matrice.
Exemple 4 d’utilisation de WordCloud: maîtrise des couleurs
Si vous souhaitez que les couleurs restent par exemple dans une teinte bleue, on peut faire comme ceci:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from random import randint
def couleur(*args, **kwargs):
return "rgb(0, 100, {})".format(randint(100, 255))
Fichier = open('texte.txt', 'r' , encoding='utf-8')
texte = Fichier.read()
Fichier.close()
mask = np.array(Image.open("coeur.png"))
mask[mask == 1] = 255
mots_exclus = ['d', 'du', 'de', 'la', 'des', 'le', 'et', 'est', 'elle', 'une', 'en', 'que', 'aux', 'qui', 'ces', 'les', 'dans', 'sur', 'l', 'un', 'pour', 'par', 'il', 'ou', 'à', 'ce', 'a', 'sont', 'cas', 'plus', 'leur', 'se', 's', 'vous', 'au', 'c', 'aussi', 'toutes', 'autre', 'comme']
wordcloud = WordCloud(background_color = 'white', stopwords = mots_exclus, max_words = 50, mask = mask).generate(texte)
plt.imshow(wordcloud.recolor(color_func = couleur))
plt.axis("off")
plt.show()


Implémenter son propre nuage de mots en Python
Ce que fait wordcloud, c’est bien beau, mais cela peut ne pas convenir à certaines personnes. Me concernant, je n’aime pas trop les mots écrits verticalement.
Je vais donc écrire ma propre fonction dont le cahier des charges sera simple:
- la fonction devra s’appeler nuage et prendra pour arguments: un nom de fichier dans lequel se trouve un texte, un 2-uplet (w,h) représentant la largeur et la hauteur de l’image à produire;
- la taille maximale d’un mot (en pixel) devra être égale au cinquième du minimum des dimensions de l’image (min(w,h));
- la taille de chaque mot devra être proportionnelle à son poids (le nombre d’occurrences du mot)
Allez! C’est parti!
Préliminaires
Compter les mots dans une chaîne de caractères
Je vais d’abord créer une fonction prenant en argument un texte, et qui retourne un dictionnaire contenant les mots du texte ainsi que leurs occurrences dans le texte.
def create_dic(texte):
D = {}
P = [ "'" , "." , ";" , "," , ":" , "!" , "?" , "(" , ")" , "&" , "%" ]
for i in P:
texte = texte.replace(i," ")
T = [ i.lower() for i in texte.split() if len(i) >= 2 ]
for i in T:
if i not in D:
D[i] = T.count(i)
return DJe choisis délibérément d’exclure les ponctuations et autres glyphes (qui ne sont pas des mots).
Calculer les dimensions d’un mot
Je vais ici reprendre un code trouvé sur Stackoverflow:
def get_text_dimensions(text_string, font):
# https://stackoverflow.com/a/46220683/9263761
ascent, descent = font.getmetrics()
text_width = font.getmask(text_string).getbbox()[2]
text_height = font.getmask(text_string).getbbox()[3] + descent
return (text_width, text_height)Cette fonction permet de retourner les dimensions d’un mot (en pixels) sachant la taille de la fonte utilisée. Ce sera bien utile pour insérer le mot dans l’image-nuage.
Création du nuage de mots
def nuage( fichier , size ):
Fichier = open(fichier, 'r' , encoding='utf-8')
texte = Fichier.read()
Fichier.close()
exclusion = ['du', 'de', 'la', 'des', 'le', 'et', 'est', 'elle', 'une', 'en', 'que', 'aux', 'qui', 'ces', 'les', 'dans', 'sur', 'un', 'pour', 'par', 'il', 'ou', 'ce', 'sont', 'cas', 'plus', 'leur', 'se', 'vous', 'au', 'aussi', 'toutes', 'autre', 'comme']
mots = create_dic(texte)
max_size = min(size[0],size[1])//3 # taille maximale d'un mot
w,h = size[0], size[1]
cloud = Image.new("RGB", (w, h), 'white')
d = ImageDraw.Draw(cloud)
m = max( [ value for key, value in mots.items() ] )
for key, value in sorted( mots.items() , key = lambda x:x[1]):
if key not in exclusion:
fontsize = int(max_size*value/m)
font = ImageFont.truetype("arial.ttf", fontsize)
x_max = w - get_text_dimensions(key,font)[0] - 20
y_max = h - get_text_dimensions(key,font)[1] - 20
x, y = randint(20,x_max) , randint(20,y_max)
d.text((x, y), key ,font=font, fill=(randint(1,255), randint(1,255), randint(1,255)))
cloud.show()Ce qui donne, pour le même texte que précédemment:
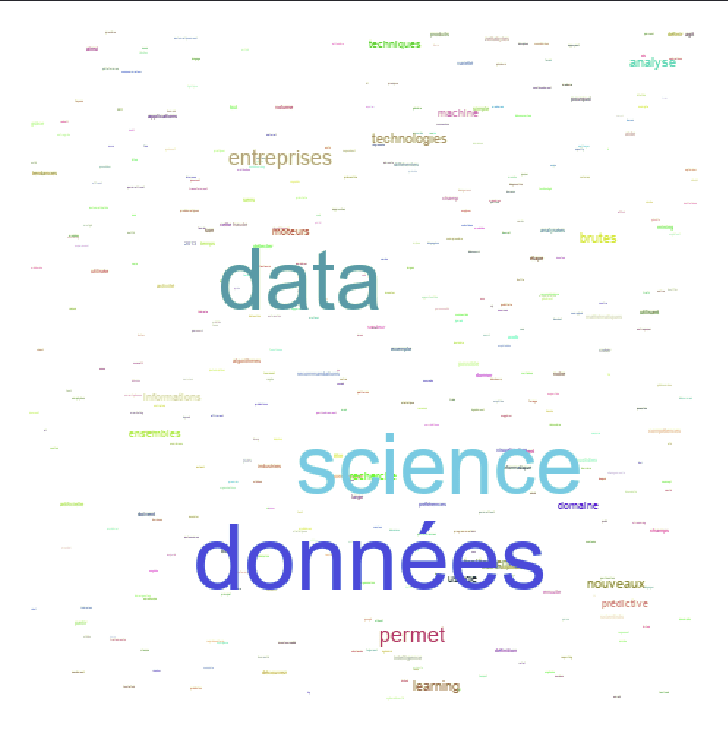
Ouais, c’est vrai, c’est moins beau que le résultat fournit par wordcloud… mais tellement plus représentatif!
En effet, on voit clairement ici que les mots « données », « data », « science » sont prépondérants par rapport aux autres, ce qui est bien le rôle d’un nuage de mots non ?
Si maintenant on souhaite y voir un peu plus, on peut exclure ces trois mots. Il me faut changer alors légèrement le code:
from PIL import Image, ImageDraw, ImageFont
from random import randint
def get_text_dimensions(text_string, font):
# https://stackoverflow.com/a/46220683/9263761
ascent, descent = font.getmetrics()
text_width = font.getmask(text_string).getbbox()[2]
text_height = font.getmask(text_string).getbbox()[3] + descent
return (text_width, text_height)
def create_dic(texte, exclusion):
D = {}
P = [ "'" , "." , ";" , "," , ":" , "!" , "?" , "(" , ")" , "&" , "%"]
for i in P:
texte = texte.replace(i," ")
T = [ i.lower() for i in texte.split() if len(i) >= 2 and i not in exclusion ]
for i in T:
if i not in D:
D[i] = T.count(i)
return D
def nuage( fichier , size ):
Fichier = open(fichier, 'r' , encoding='utf-8')
texte = Fichier.read()
Fichier.close()
exclusion = [ 'data', 'science' , 'données', 'du', 'de', 'la', 'des', 'le', 'et', 'est', 'elle', 'une', 'en', 'que', 'aux', 'qui', 'ces', 'les', 'dans', 'sur', 'un', 'pour', 'par', 'il', 'ou', 'ce', 'sont', 'cas', 'plus', 'leur', 'se', 'vous', 'au', 'aussi', 'toutes', 'autre', 'comme']
mots = create_dic(texte , exclusion)
max_size = min(size[0],size[1])//3 # taille maximale d'un mot
w,h = size[0], size[1]
cloud = Image.new("RGB", (w, h), 'white')
d = ImageDraw.Draw(cloud)
m = max( [ value for key, value in mots.items() ] )
for key, value in sorted( mots.items() , key = lambda x:x[1]):
if key not in exclusion:
fontsize = int(max_size*value/m)
font = ImageFont.truetype("arial.ttf", fontsize)
x_max = w - get_text_dimensions(key,font)[0] - 20
y_max = h - get_text_dimensions(key,font)[1] - 20
x, y = randint(20,x_max) , randint(20,y_max)
d.text((x, y), key ,font=font, fill=(randint(1,255), randint(1,255), randint(1,255)))
cloud.show()
if __name__ == "__main__":
nuage( 'texte.txt' , (500,500) )Cela donne, pour notre exemple:
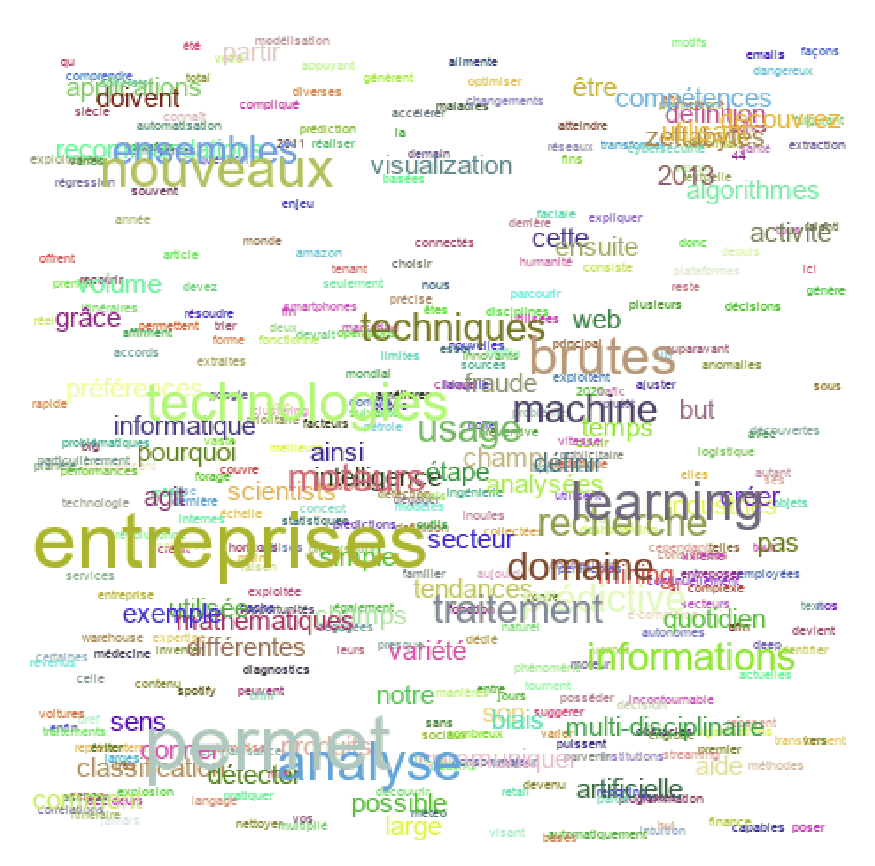
On peut trouver qu’il y a trop de mots et vouloir limiter le nombre de mots à 50 (par exemple). On peut alors introduire un paramètre:
def nuage( fichier , size , MAX_COUNTER = 50):
Fichier = open(fichier, 'r' , encoding='utf-8')
texte = Fichier.read()
Fichier.close()
counter = 0
exclusion = [ 'data', 'science' , 'données', 'du', 'de', 'la', 'des', 'le', 'et', 'est', 'elle', 'une', 'en', 'que', 'aux', 'qui', 'ces', 'les', 'dans', 'sur', 'un', 'pour', 'par', 'il', 'ou', 'ce', 'sont', 'cas', 'plus', 'leur', 'se', 'vous', 'au', 'aussi', 'toutes', 'autre', 'comme']
mots = create_dic(texte , exclusion)
max_size = min(size[0],size[1])//3 # taille maximale d'un mot
w,h = size[0], size[1]
cloud = Image.new("RGB", (w, h), 'white')
d = ImageDraw.Draw(cloud)
m = max( [ value for key, value in mots.items() ] )
for key, value in sorted( mots.items() , key = lambda x:x[1] , reverse=True):
if key not in exclusion and counter <= MAX_COUNTER:
fontsize = int(max_size*value/m)
font = ImageFont.truetype("arial.ttf", fontsize)
x_max = w - get_text_dimensions(key,font)[0] - 20
y_max = h - get_text_dimensions(key,font)[1] - 20
x, y = randint(20,x_max) , randint(20,y_max)
d.text((x, y), key ,font=font, fill=(randint(1,255), randint(1,255), randint(1,255)))
counter += 1
cloud.show()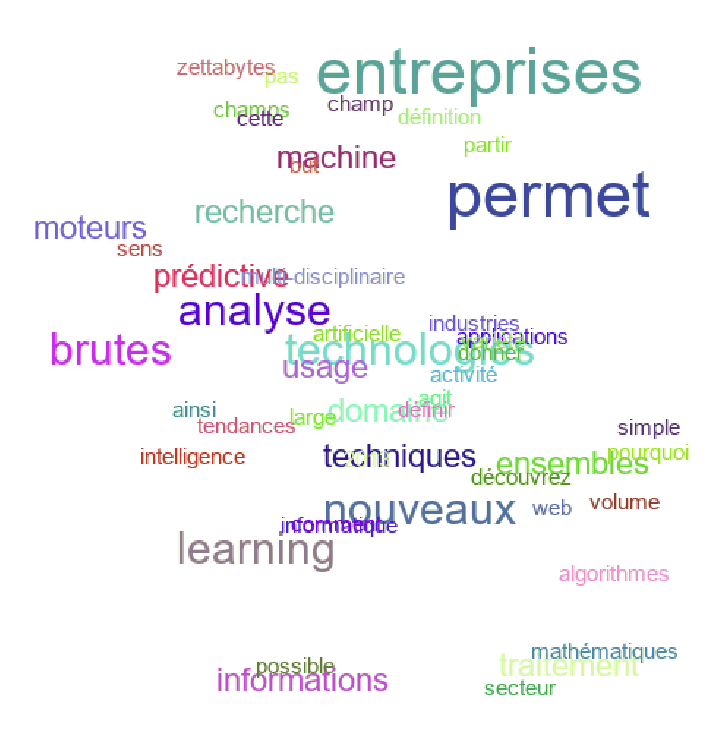
Maintenant que vous comprenez chacune des étapes, vous pouvez modifier le code à votre guise pour produire exactement ce que vous voulez.


